LLMs have demonstrated remarkable abilities at interacting with humans through language, especially with the usage of instruction-following data. Recent advancements in LLMs, such as MiniGPT-4, LLaVA, and X-LLM, further enlarge their abilities by incorporating multi-modal inputs, including image, video, and speech. Despite their effectiveness at generating precise and detailed language understanding of the given modality signal, these LLMs give up the ability to ground specific parts of inputs, thus only constructing a coarse-grained mapping. However, explicit and informative correspondence between text and other modalities will not only improve the user experience but also help to expand the application scenario of multi-modal LLMs.
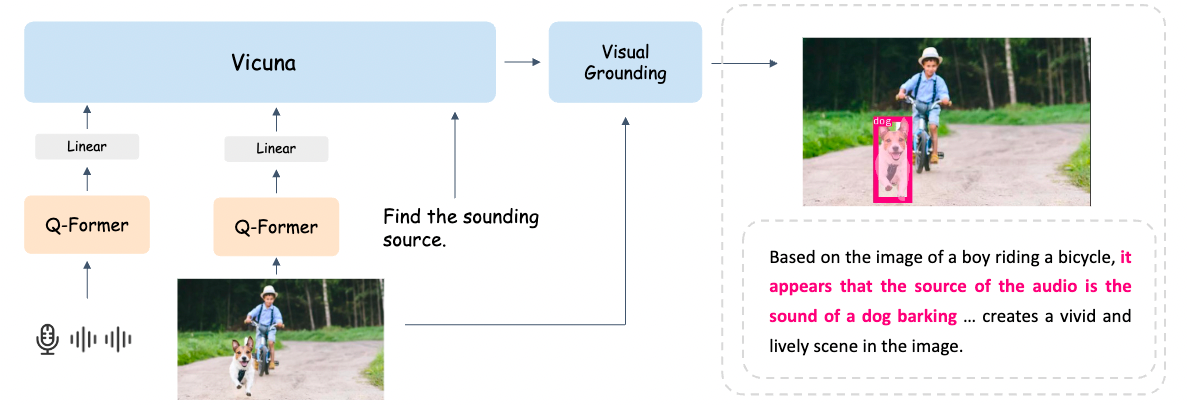
As the figure shown, we perform joint multi-modal understanding and chatting for text, vision and audio,
which is achieved by learning a shared representation space that aligns well with pre-trained Vicuna.
We also build an off-the-shelf visual grounding pipeline to explore the fine-grained relation between different visual objects and modalities.
BuboGPT connects different modality Q-Former with pre-trained large language model Vicuna, using a simple projection matrix. We consider a two-stage instruction-tuning procedure:
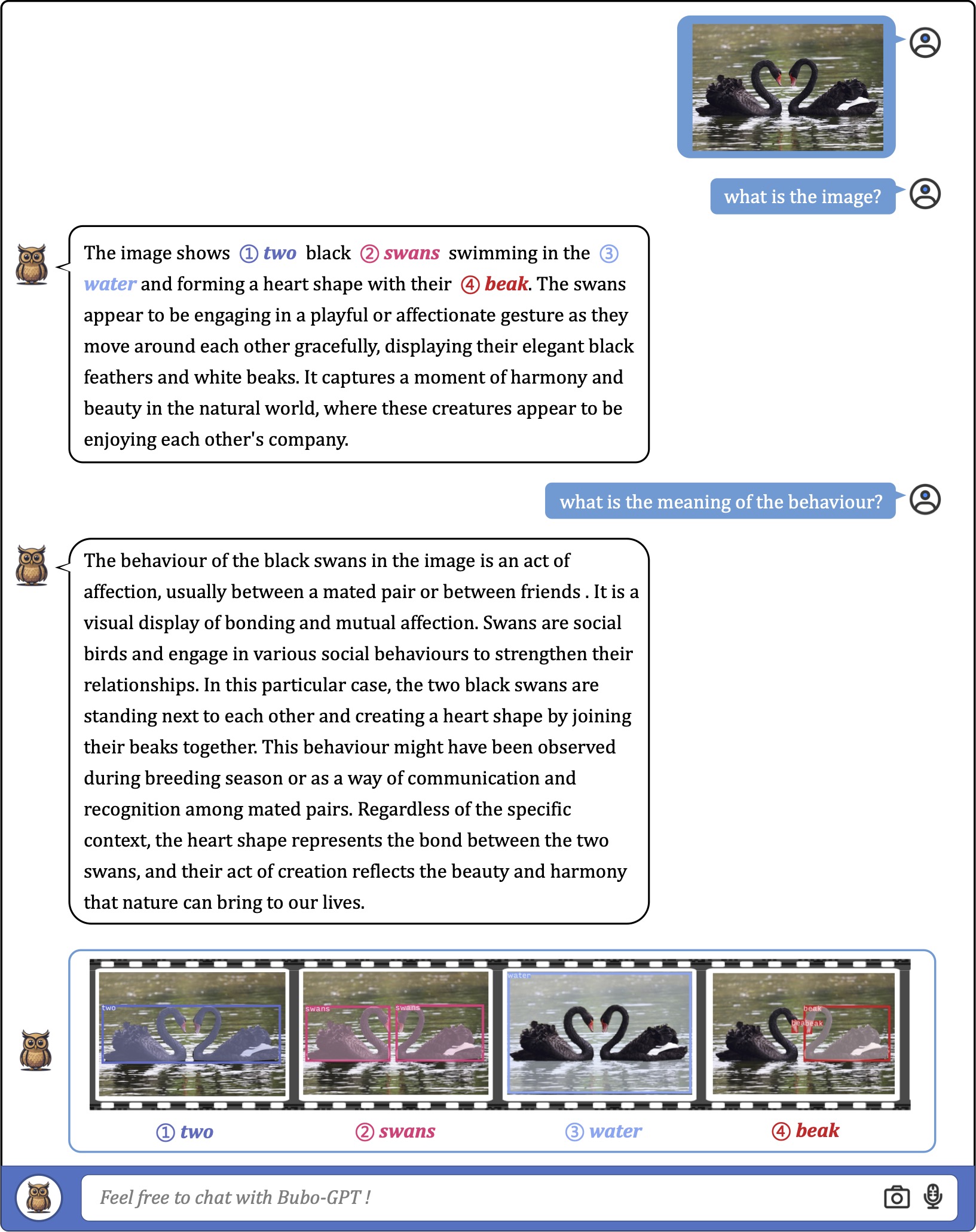
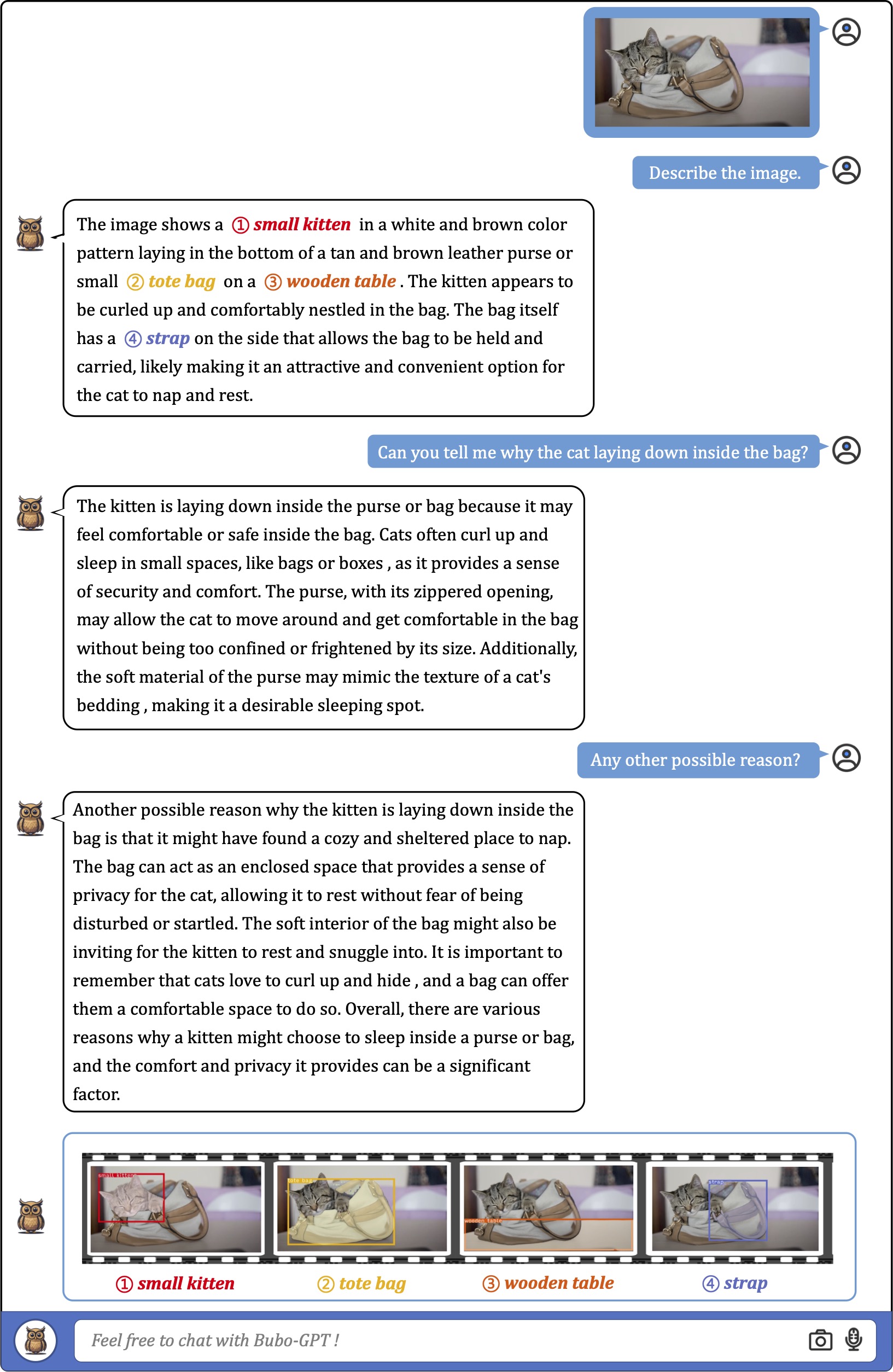
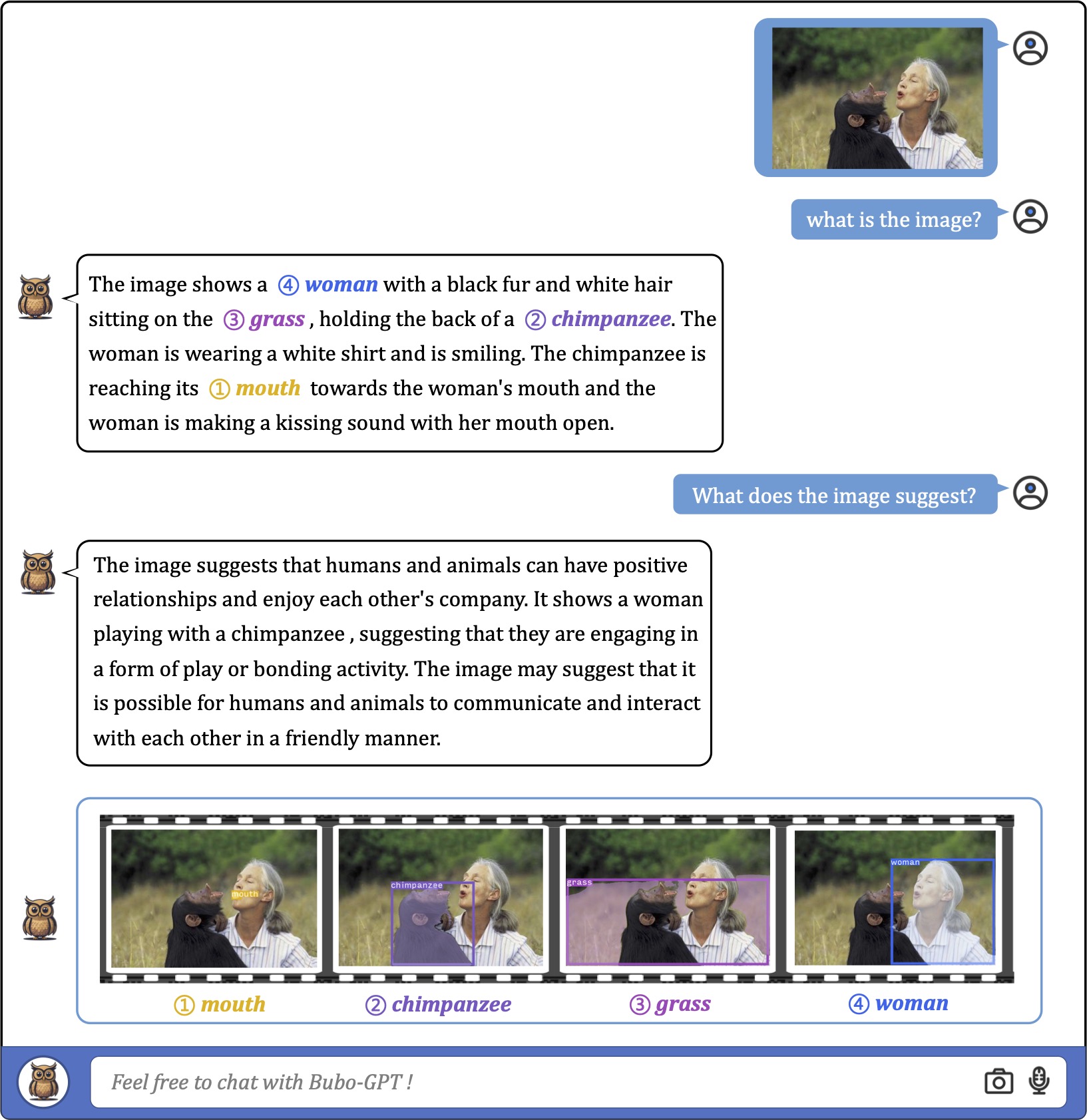
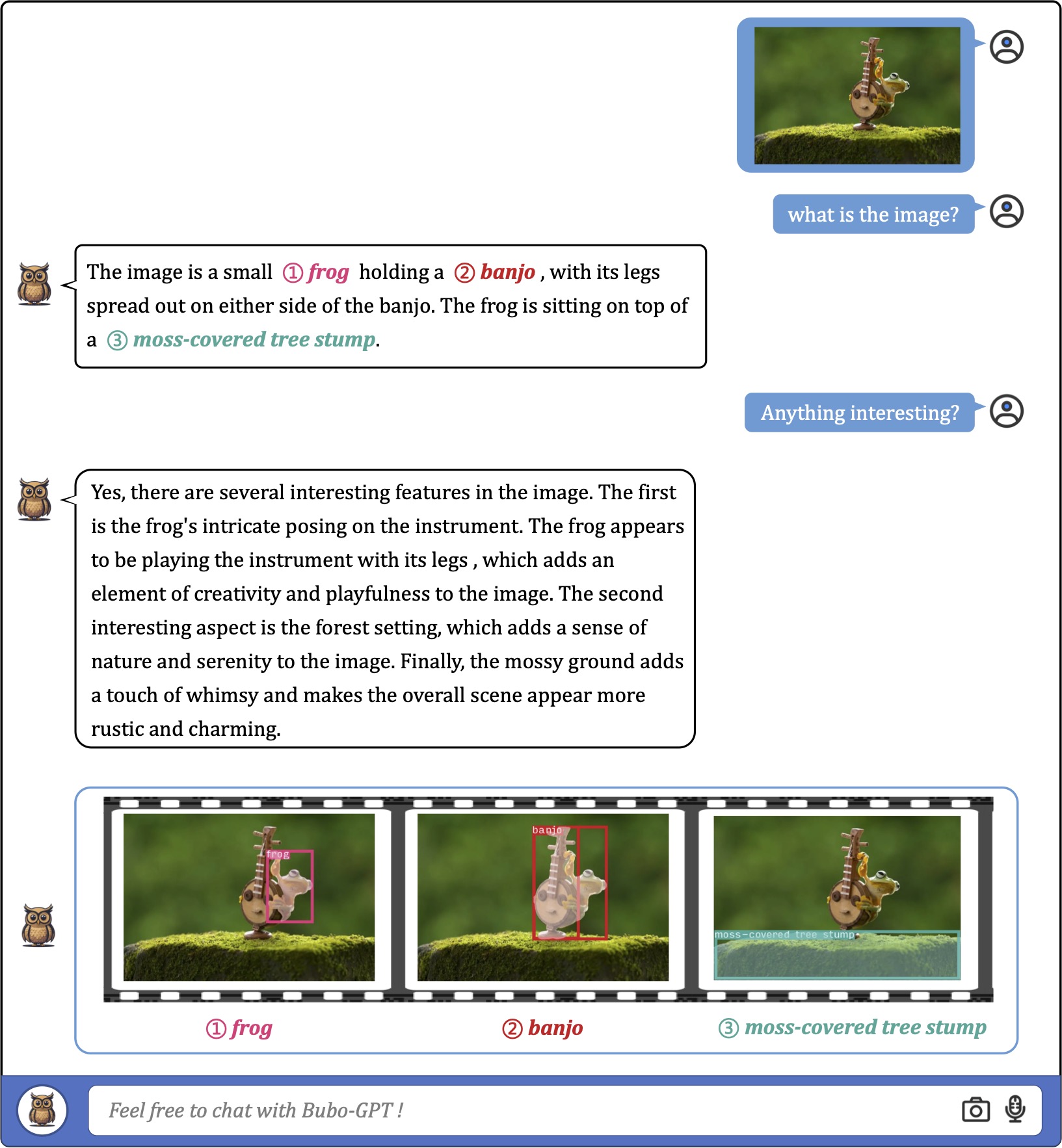
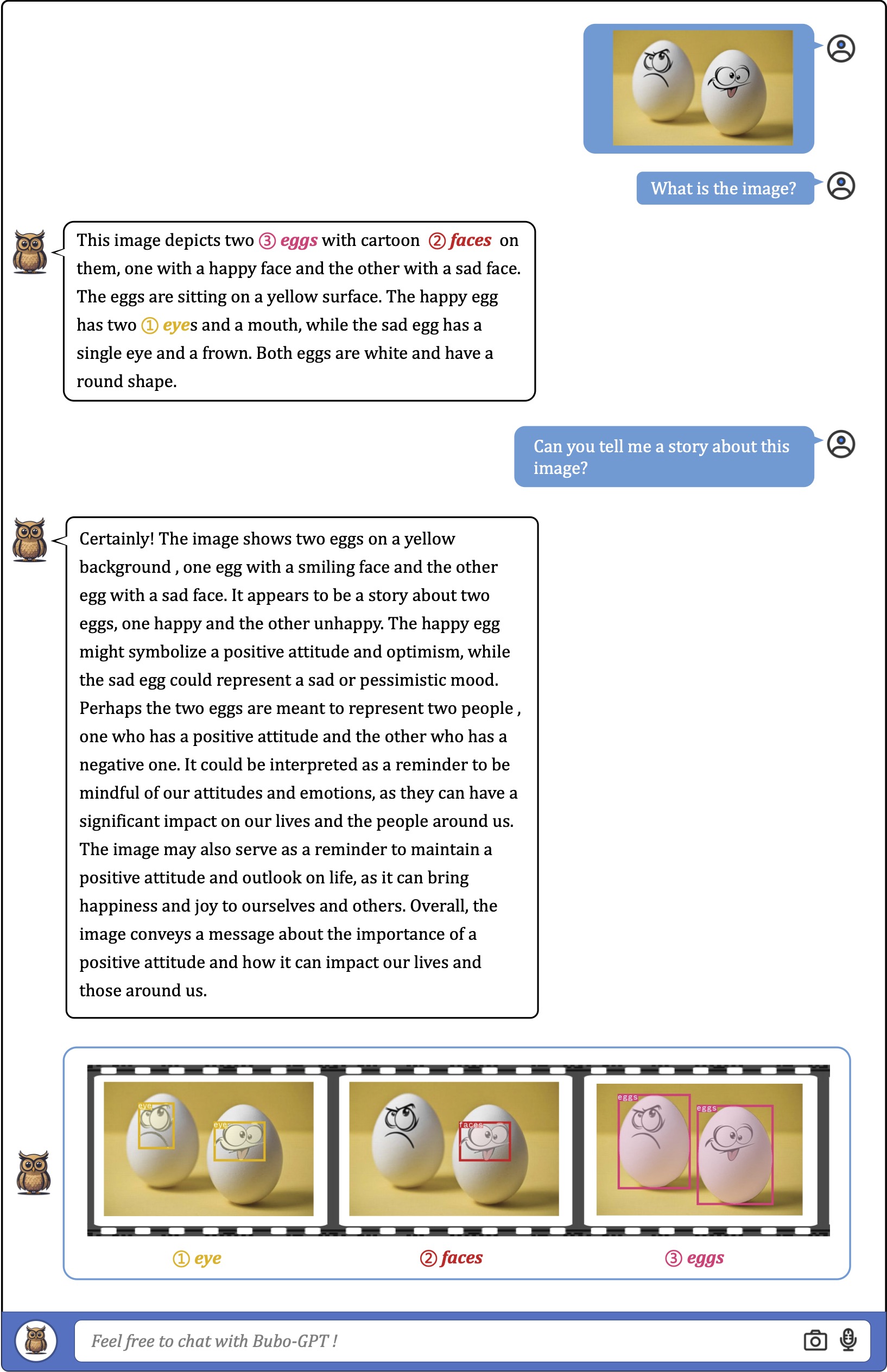
We first consider using a single image as input for fine-grained visual understanding with grounding. As the exmaples shown,
the model can accurately associate textural words or phrases with image regions in various scenarios with different complexities.
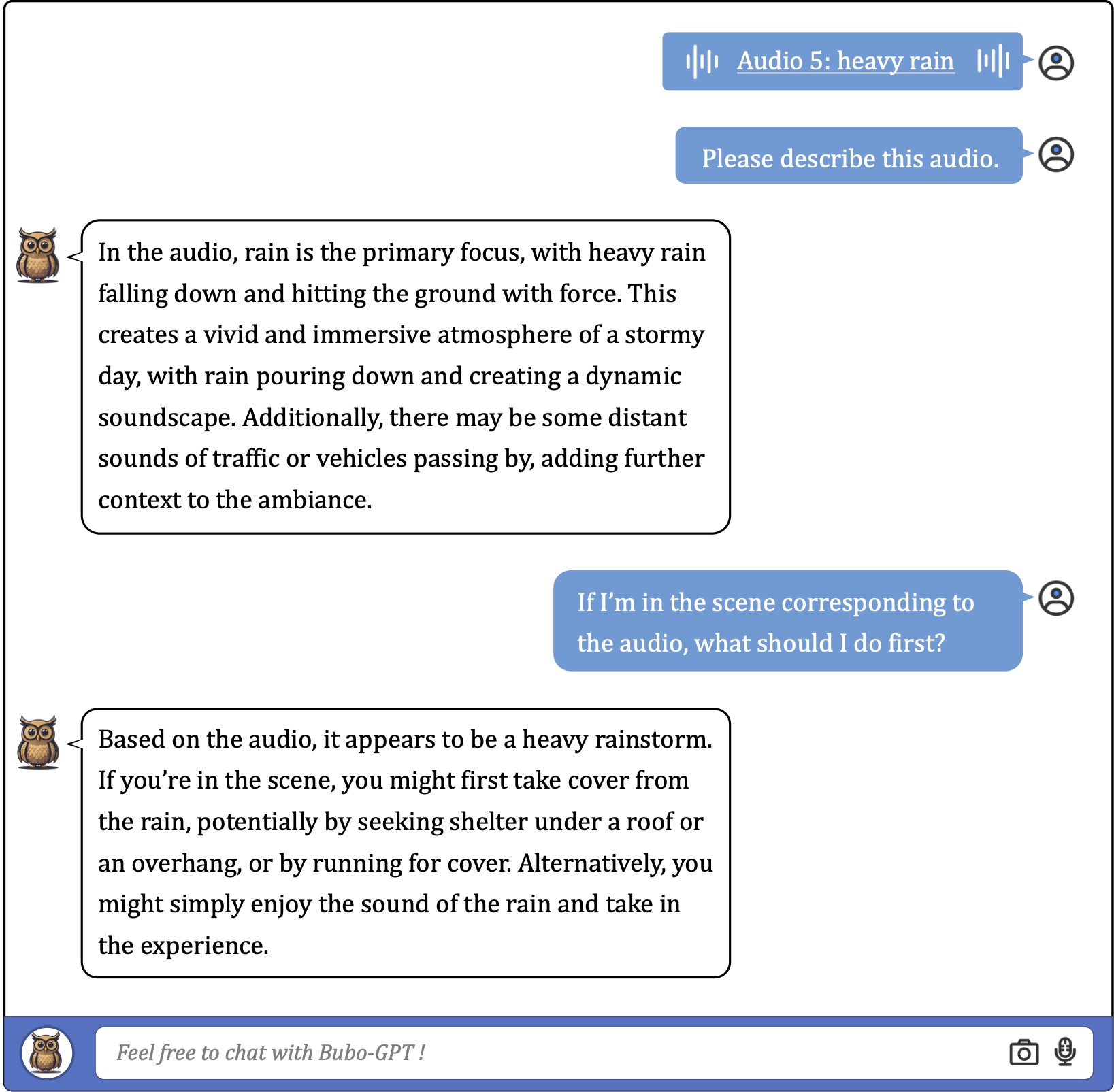
When a single audio clip is provided for audio understanding, BuboGPT gives informative descriptions covering nearly all acoustic parts included,
even when some audio fragments are too short for humans to notice, see examples for details.
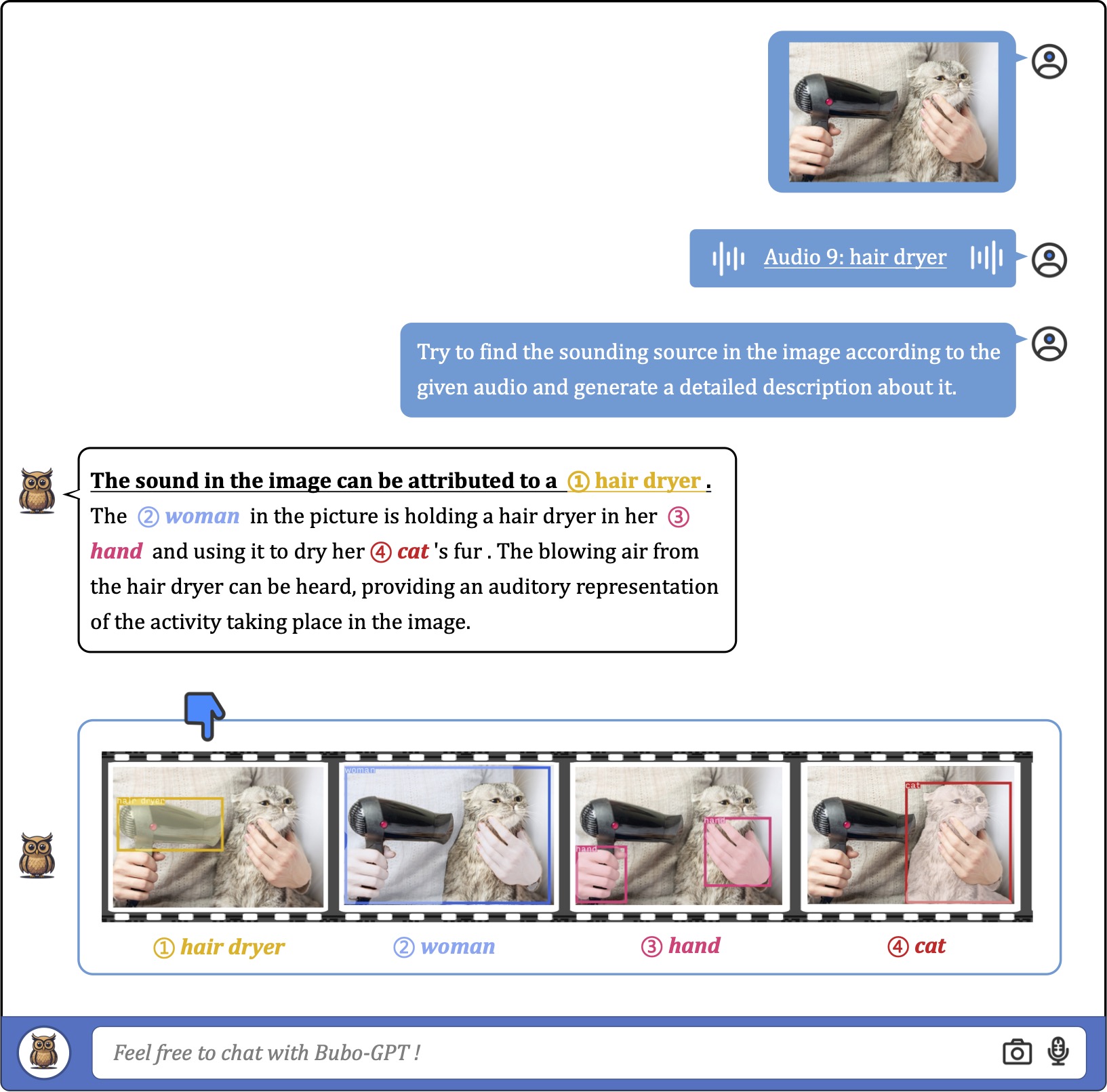
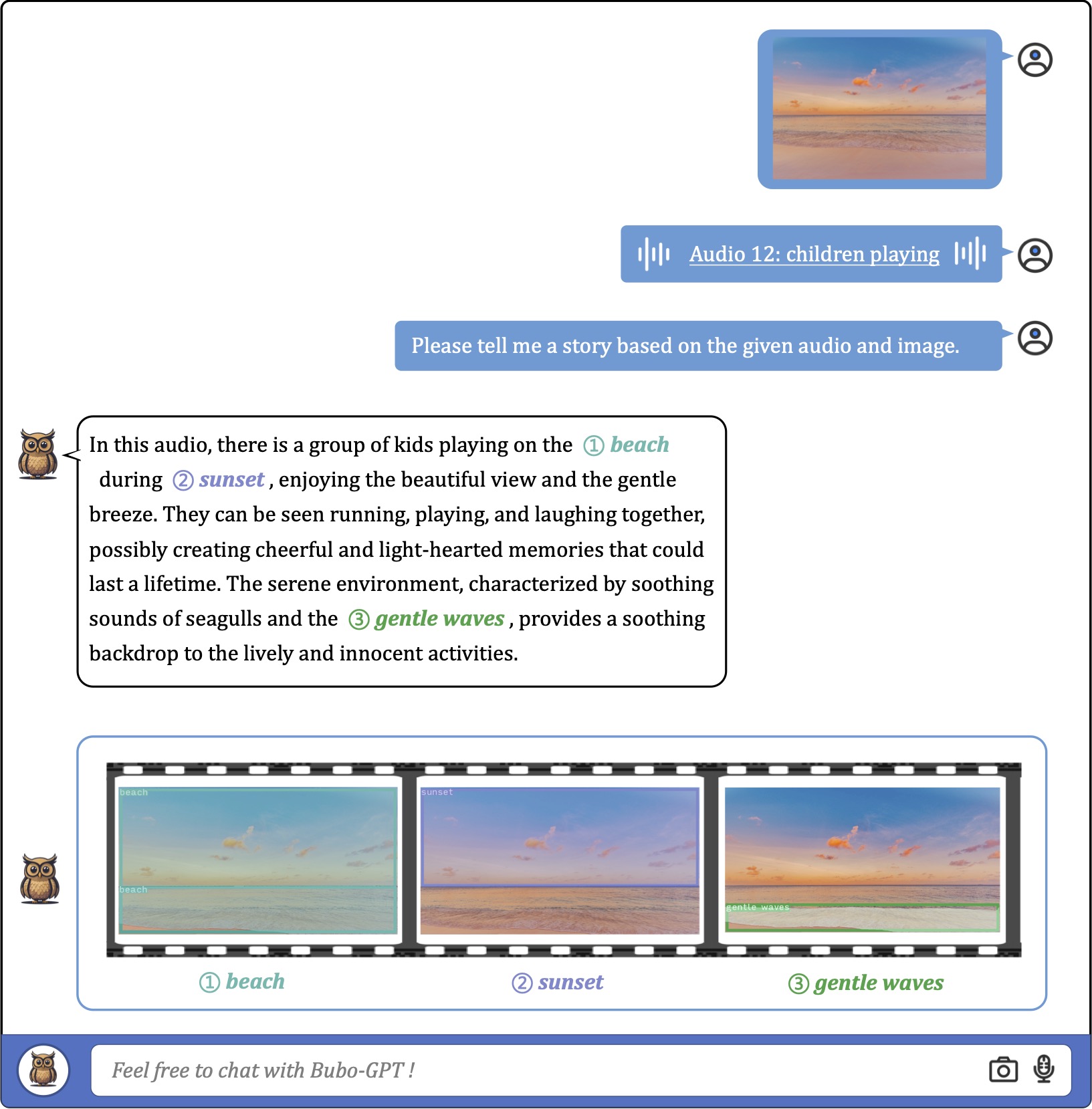
We show that BuboGPT can perform sound localization with a matched audio-image pair provided,
which gives a perfect example for aligned audio-image understanding, see examples for details.
The BuboGPT can also tell whether the image and audio are relevant to each other and generate high-quality response
for arbitrary audio-image understanding, see examples for details.
![]() BuboGPT: Training Procedure
BuboGPT: Training Procedure
![]() Examples on Fine-grained Visual Understanding
Examples on Fine-grained Visual Understanding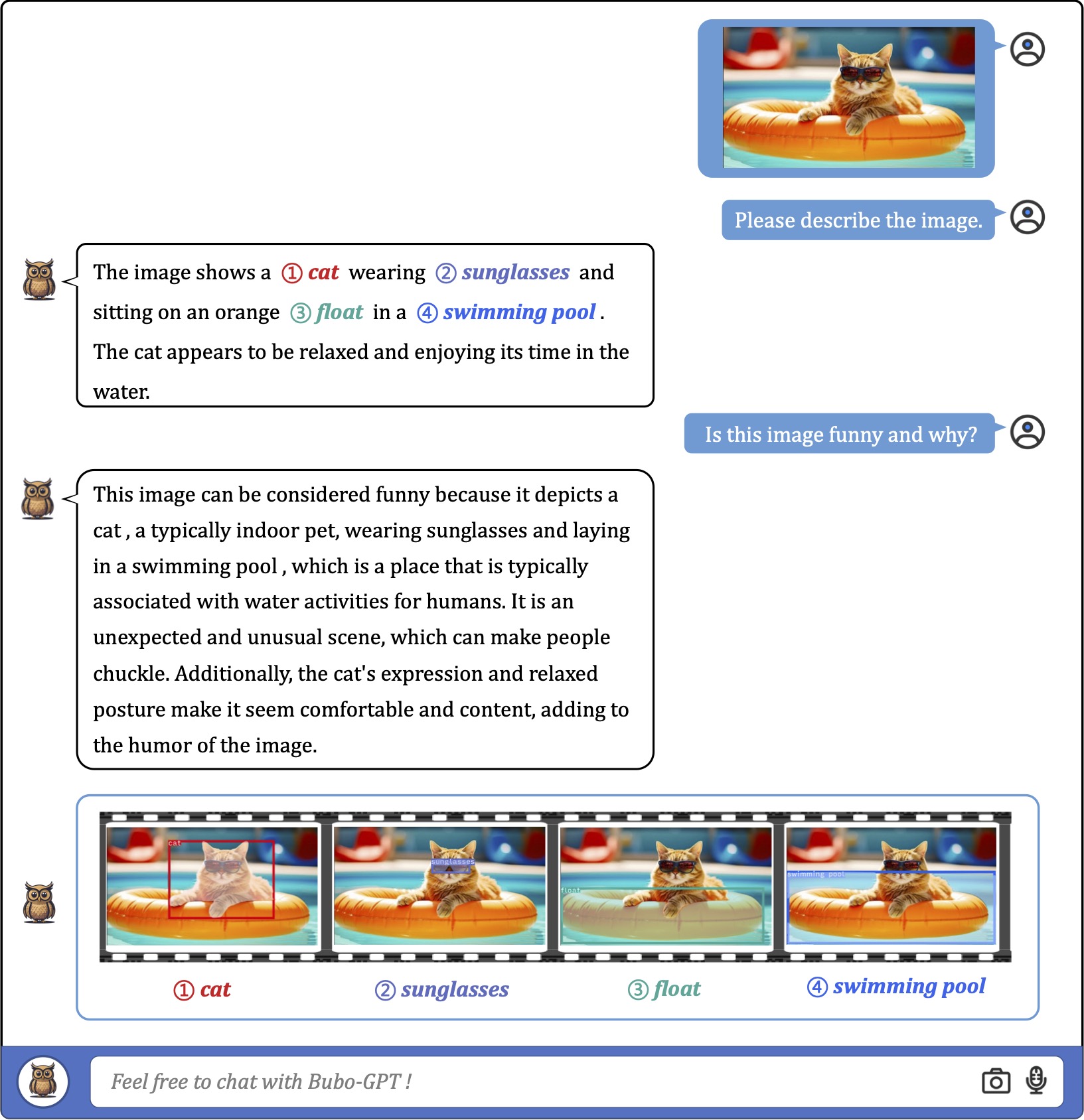
![]() Examples on Audio Understanding
Examples on Audio Understanding




![]() Examples on Aligned audio-image understanding
Examples on Aligned audio-image understanding


![]() Examples on Arbitrary audio-image understanding
Examples on Arbitrary audio-image understanding
BibTeX
@article{zhao2023bubogpt,
author = {Yang Zhao and Zhijie Lin and Daquan Zhou and Zilong Huang and Jiashi Feng and Bingyi Kang},
title = {BuboGPT: Enabling Visual Grounding in Multi-Modal LLMs},
publisher = {arXiv:2307.08581},
year = {2023}
}